
💡Bottom Line Up Front
This playbook gives federal CIOs a practical framework to stop AI-washing before contract award. You'll learn 9 technical validation questions, 6 red flags to spot fake AI claims, and how to run a proof challenge that forces vendors to demonstrate real automation capability—not just marketing slides. Vendors who can't prove their AI works on your actual workload should be scored technically unacceptable.
Introduction
Federal CIOs face conflicting pressures: move faster on AI adoption while preventing waste, fraud, and compliance failures.
The stakes are significant. Federal agencies committed $5.6 billion to AI initiatives from 2022-2024, and in FY2025 alone, federal AI R&D budgets reached $3.3 billion—nearly double the annual average from prior years. Yet 70-85% of AI projects fail to deliver expected outcomes, and only ~6% of the federal acquisition workforce has received AI-specific training. This gap between investment and capability creates risk.

Federal regulators escalated enforcement against AI-washing from civil penalties to criminal prosecution. SEC v. Delphia and Global Predictions, March 2024 ($400,000 civil penalties for false AI claims). FTC Operation AI Comply, September 2024, challenged unsupported accuracy statements. DOJ charged Nate, Inc. CEO Albert Saniger, S.D.N.Y., 2022, after claims of 93-97% automation were contradicted by manual fulfillment activity related to an automated shopping app.
As former Deputy Attorney General Lisa Monaco stated: "We will seek stiffer sentences where AI is deliberately misused to make white-collar crimes more serious."
That resolve has only strengthened under the current administration. In January 2026, the DOJ announced the creation of the National Fraud Enforcement Division, specifically to combat AI-driven fraud. Current Deputy Attorney General Todd Blanche has made it clear that "individual accountability" remains the primary goal when AI is used to create false records or defraud the public. Enforcement is no longer hypothetical.
For CIOs, that enforcement pattern changes how source selection should work. "AI-enabled" is no longer a feature claim you accept at face value. Test AI claims like any other technical assertion.
You do not need a PhD panel to do this. You need a repeatable validation routine that distinguishes three things quickly:
- Real machine learning capability
- Rules automation wrapped in AI language
- Manual labor hidden behind an interface
This post gives you that routine.
How OMB, FAR, and Source Selection Rules Work Together
Before applying validation tactics, understand how policy layers interact:
OMB M-24-10 (March 28, 2024) establishes the core governance requirements for AI use within agencies: impact assessments, continuous monitoring, meaningful human review, and acquisition guidance for purchasing AI capabilities from vendors. It applies to both your internal AI deployments and your procurement activities.
FAR Part 15.3 governs source selection procedures and contracting officer authority. OMB guidance informs but does not override agency-specific implementation or contracting officer judgment in award decisions.
This playbook aligns with both layers while respecting the contracting officer's final determination authority.
Why You Need to Catch AI-Washing Before Award
Most federal teams fail not because they skipped policy, but because they accepted polished claims without testing them under realistic conditions.
The consequences are not theoretical. In 2025, GAO sanctioned parties in at least 9 bid protests involving AI-generated fabricated legal citations. When vendors submit fake AI outputs in source selection, agencies face protest risk and reputational damage.
The cost of that mistake is measurable:
- Rework after award through contract modifications and deliverable disputes
- Delayed mission outcomes while technical teams unwind architecture assumptions
- Oversight exposure when claims cannot be substantiated during audit
And the opportunity cost is just as important. While teams are cleaning up a bad award, other valid high-value use cases wait in backlog.
Move technical validation into source selection and make it a gate, not a post-award discovery exercise.
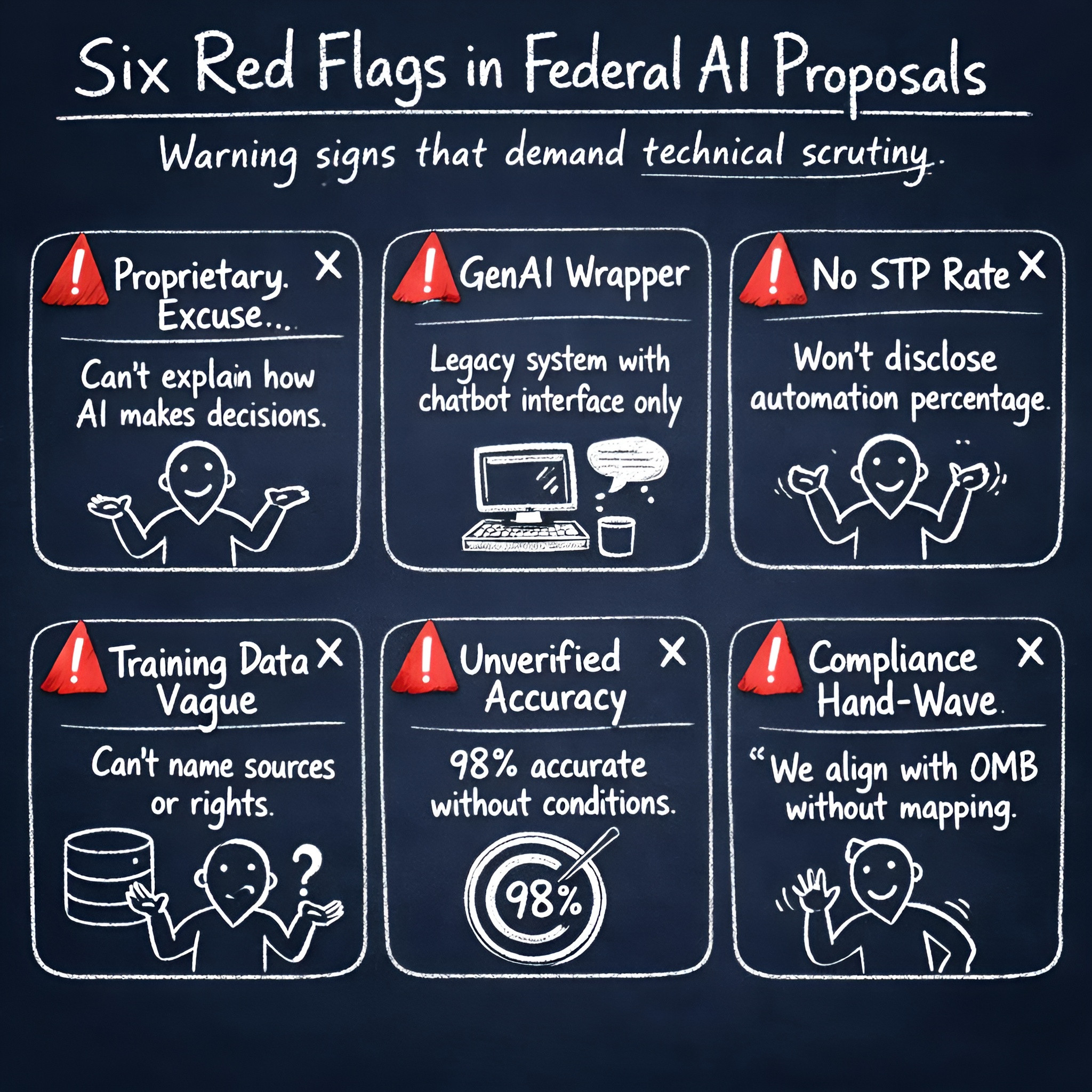
The 6 Red Flags You Can Spot in Government AI Proposals
These patterns signal increased technical risk:
Red Flag 1: Black Box Defense
Vendors who use "proprietary" as a substitute for explainability—unable to explain model behavior, data flow, and decision pathways in clear language—create governance risks you cannot satisfy.
Red Flag 2: GenAI Wrapper
Deterministic if/then routing rules disguised by only a chat layer "AI" element suggests cosmetic value, not true machine learning capability.
Red Flag 3: No straight-through processing rate
Vendors who won't disclose automated completion rates, exception rates, and manual intervention levels hide the true labor cost of their "AI" solution.
Red Flag 4: Training data ambiguity
Vague descriptions of training corpus, legal rights, update cadence, and drift controls indicate poor data governance and unquantified model risk.
Red Flag 5: Accuracy claims without independent conditions
"98% accurate" without false positive/negative rates on benchmarks matching your operational context is marketing, not measurable evidence.
Red Flag 6: Compliance language without controls
Stated alignment with federal guidance without mapped technical controls and audit evidence indicates assurances without implementation.
Use the nine questions below to validate any vendor showing these warning signs.
The 9-Question Technical Validation Playbook
Use this table during source selection to standardize scoring across vendors:
Swipe horizontally to view all columns
| Question | Required Artifact | Positive Signal | Disqualifying Condition |
|---|---|---|---|
| 1. Where is this model currently deployed in a production environment? | 2 reference deployment contracts or client verification letters | Specific agency names, comparable data volumes, production dates | No verifiable production instances; only pilot/demo environments |
| 2. What learning method is active in the deployed system? | Architecture diagram + technical documentation naming algorithms/approaches | Named ML approach (supervised/unsupervised/RL*), specific workflow component controlled *RL = Reinforcement Learning | Rules-based logic only; no adaptive capability demonstrated |
| 3. What is the performance delta versus the non-AI baseline? | Baseline vs. AI metrics report with methodology | Quantified improvement >20% on comparable workload; statistical significance noted | No baseline comparison; cherry-picked metrics without context |
| 4. What is the straight-through processing (STP) rate for this workload? | 90-day operational metrics dashboard | STP rate >70% with documented exception handling | STP rate <50% or undisclosed manual intervention levels |
| 5. Exactly where do humans intervene in the loop, and why? | Process flow with decision trees and escalation triggers | Clear intervention triggers, role definitions, audit trails | Vague "as needed" language; no documented decision logic |
| 6. Are you using offshore or third-party labor to process exceptions? | Data flow diagram + security control documentation | Onshore processing or documented FedRAMP boundary controls | Undisclosed offshore processing of sensitive data; missing DPA* *DPA = Data Processing Agreement |
| 7. What specific data trained this model, and what rights do you hold? | Data source inventory with licensing documentation | Specific source names, legal rights verified, update cadence defined | Proprietary data claims without disclosure; unlicensed source usage |
| 8. Does your system use government-provided data to retrain its models? | Contract clause template + opt-out mechanism | Explicit prohibition on commercial model training without consent | Ambiguous language allowing vendor interpretation |
| 9. How does the system automatically detect and alert on model drift or bias? | Monitoring dashboard + threshold documentation + response procedures | Automated drift detection with defined thresholds; bias testing methodology | No monitoring; reactive-only approach to model degradation |
Scoring Guidance: Vendors scoring 2+ disqualifying conditions, or unable to provide documented evidence, should be marked technically unacceptable for AI capability claims, pending contracting officer review.
Download the Complete Evaluation Checklist
Get the printable scorecard, acceptable evidence rubrics, and evaluator templates for all 9 questions.
Real Examples: What Working AI Looks Like in Government
Fake AI survives because evaluations stop at slides and demos. Capability claims gain credibility when validated against a constrained, mission-relevant workload.
Consider two federal examples that demonstrate what validated AI can deliver:
IRS Enterprise Case Management (ECM): The reported outcome was 1,466 contract modifications completed in approximately 72 hours, work that previously consumed roughly 1.5 staff work-years. That result came from narrow scope, prepared process inputs, and proof under execution conditions.
Army DORA Bot: Contractor vetting was reduced from 2-3 hours per transaction to approximately 5 minutes. The system automatically verifies vendor financial and performance records—a narrow, high-value use case with measurable outcomes.

Here's how to copy that pattern in source selection:
Run a coding challenge style proof event before award:
- Provide a bounded sample dataset that mirrors your operational edge cases
- Define pass/fail metrics in advance (accuracy, cycle time, exception handling, auditability)
- Require live execution with your evaluators observing output and logs
- Score vendors on evidence, not presentation quality
This does two things. It exposes inflated claims quickly, and it rewards vendors who have built production-grade delivery discipline.
A simple rule works well: if the vendor asks to replace your sample with their curated demo data, stop and reset the session. Curated demos do not prove mission fit.
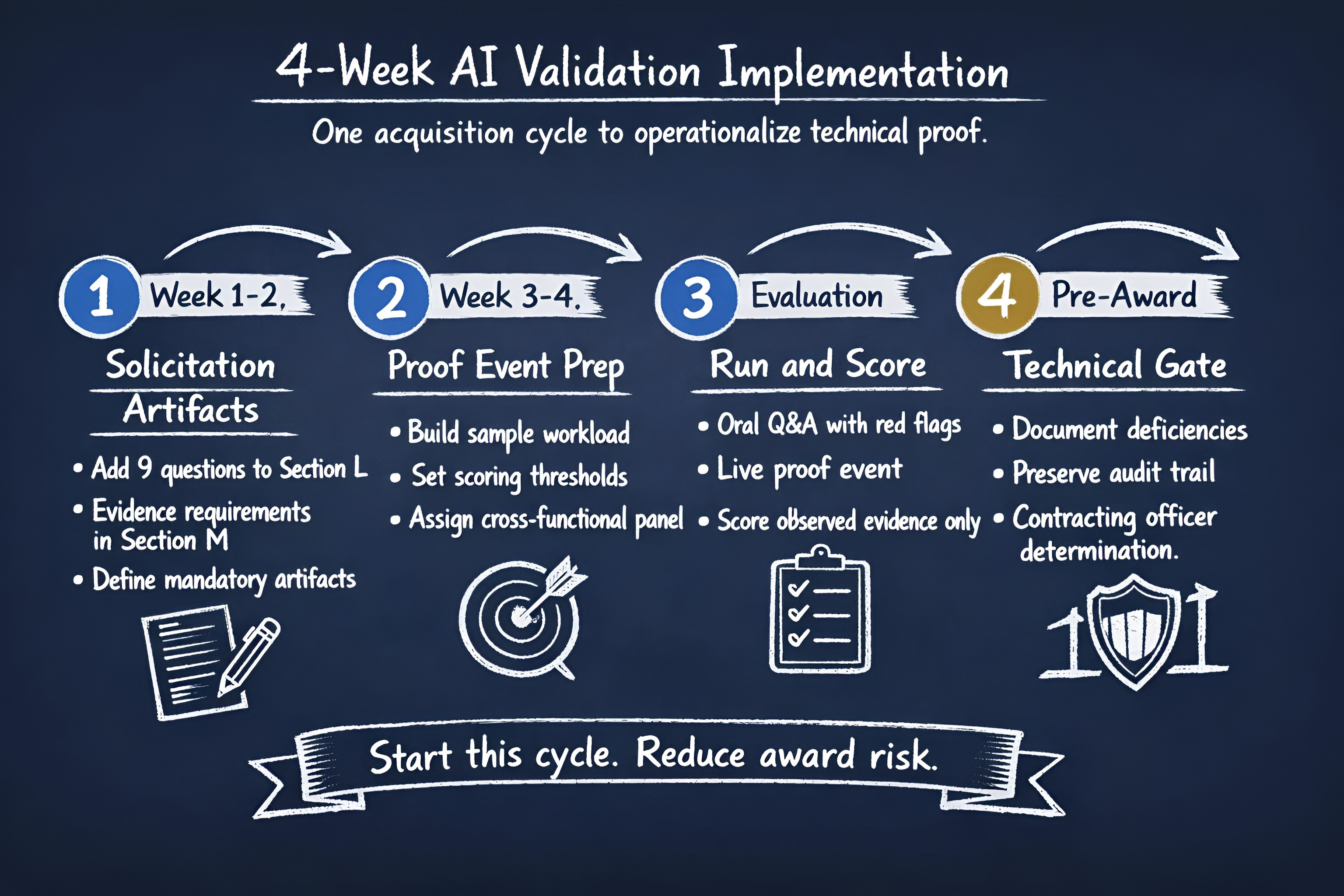
How to Start: A 4-Week Implementation Plan
You can operationalize this in one acquisition cycle.
| 1 | Week 1-2: Insert validation language into solicitation artifactsAdd the nine questions to Section L response instructions. Add evidence requirements to Section M technical scoring. Define mandatory artifacts (architecture map, metrics, data rights statement, control mapping). |
| 2 | Week 3-4: Prepare the proof eventBuild a sample workload with known edge cases. Set scoring thresholds for automation, error profile, and explainability. Assign a cross-functional panel: product, engineering, security, acquisition, legal. |
| 3 | Evaluation period: Run and scoreConduct oral Q&A using the six red flags and nine questions. Execute the live proof event with common conditions for all vendors. Score only what is observed and documented. |
| 4 | Pre-award gate: Decide on technical acceptabilityDocument the deficiency for technical unacceptability scoring when evidence fails to support AI claims. Preserve documentation trail for defensibility during protest or audit. |
This approach helps agencies evaluate whether proposed pricing aligns with actual delivered capability.
Final Recommendation
Government teams need procurement mechanics that force proof.
Use the six red flags to identify risk fast. Use the nine questions to require technical substance. Use the IRS-style challenge model to validate capability before award.
Use those three steps consistently, and you'll reduce award risk, improve mission outcomes, and protect your agency from preventable AI-washing failures.
Get the ready-to-use checklist here: AI Capability Proof Checklist
References
[2] Department of Justice, AI Use Case Inventory - Updated 2025.
[3] U.S. Department of Justice, Press Release: "CEO of Automated Shopping App Charged with Securities Fraud and Wire Fraud," 2022 — U.S. v. Albert Saniger, S.D.N.Y.
[4] SEC Press Release 2024-25: "SEC Charges Two Companies with AI Washing," March 18, 2024 — SEC v. Delphia (USA) Inc. and Global Predictions Inc., $400,000 civil penalties.
[5] Federal Trade Commission, "FTC Cracks Down on Fraudulent AI Claims and Schemes," September 2024 — Operation AI Comply.
[7] Federal Acquisition Regulation, Part 15.3 - Source Selection.
[8] Shanna Webbers (Chief Procurement Officer, IRS), "Making Strategic Decisions Through Opposition and Uncertainty," NCMA Contract Management Magazine — documents 1,466 contract modifications and ~72-hour execution during Section 889 implementation.
⚠️Policy Boundary
This playbook provides recommended evaluation practices for source selection teams. Final determinations of technical acceptability rest with the contracting officer and source selection authority per FAR 15.3. OMB M-24-10 establishes governance and acquisition requirements for agency AI use. These guidelines inform but don't replace your contracting officer's judgment or agency-specific rules.